由 darkranger 在 週曰, 10/15/2017 - 20:58 發表,更新日期:週二, 10/17/2017 - 10:58
由 darkranger 在 週六, 09/09/2017 - 17:54 發表
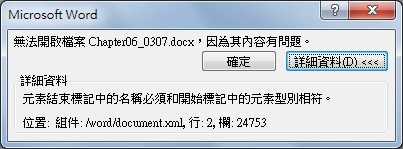
前陣子 DR 在 Word 2010 上編輯某份 DOCX 檔案時,因不明原因導致 Word 異常終止。之後再次開啟相同檔案時,便出現「元素結束標記中的名稱必須和開始標記中的元素型別相符」(The name in the end tag of the element must match the element type in the start tag)這項錯誤,並列出錯誤位置。由於錯誤細節好像還算明確,讓 DR 一度覺得這似乎是個有機會人工解決的問題。
由 darkranger 在 週六, 06/17/2017 - 19:55 發表,更新日期:週四, 06/22/2017 - 21:37
繼文字介面的聖經搜尋工具後,DR 再一次設法突破 N900 的應用極限……而這次的目標是試圖做出 Yahoo 奇摩字典的文字介面版本。雖然使用奇摩字典聽起來是個再簡單不過的動作,但由於 N900 的硬體規格相當古老,若透過網頁瀏覽器操作,則其效率很難令人滿意。因此如果能夠用一支更加簡單的工具來送出查詢並取得結果,自然是方便許多。
事實上 DR 並不是很喜歡這種用工具擷取網頁資料的方案,由於這類工具規避了使用者直接瀏覽網頁的動作,所以如果網站擁有者擔心此舉損害了自己的利益(例如廣告收益),很容易就可以做出修改來使工具失效,造成程式的可靠性難以保障。不過至少目前為止,這支搜尋工具與伺服器之間是相安無事的。
由 darkranger 在 週六, 04/08/2017 - 22:14 發表,更新日期:週四, 11/30/2017 - 10:09
日前 DR 處理公司一部仍在使用 Windows XP 的電腦,但卻在操作登錄編輯程式(regedit)時,不慎誤刪了一個項目,如下:HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Class\{4d36e96b-e325-11ce-bfc1-08002be10318}\UpperFilters。結果重開機後便造成鍵盤在 Windows 裡完全沒反應,改插其它鍵盤也是一樣。
事實上不只是舊版 Windows 會這樣,後來 DR 也在 Windows 10 上測試過,若刪除該機碼也會有相同的結果。然而只是誤刪一個機碼,鍵盤就完全不能用,毫無自動復原的機制……如此這般設計會不會太誇張了一點?
由 darkranger 在 週六, 01/07/2017 - 14:09 發表,更新日期:週一, 01/09/2017 - 09:29
新年伊始,又到了電腦除舊佈新的時間了。於是 DR 最近便將剛停止維護的 Fedora 23,以全新安裝的方式升級到目前最新的 Fedora 25。儘管這道作業流程 DR 已經執行過蠻多次了,但這次卻在安裝完畢後,遇到兩項少見的問題。

由 darkranger 在 週六, 12/03/2016 - 14:40 發表,更新日期:週五, 02/24/2017 - 17:30
在最近兩年的工作經歷裡,DR 時常需要為著各種目的,一次性處理大量的 Word 文件。例如繁簡轉換、搜尋及取代多組文字、以及為特定文字標上黃色背景,以利後續人工檢查時能夠特別留意等等……於是 DR 便撰寫了兩支輔助工具來應付這些需求。
這兩支工具都是使用 Python 撰寫的,其中第一支工具的作用是藉由控制 Microsoft Word 來完成各種批次處理。由以下抓圖可知,這支工具能夠對指定目錄中的所有 Word 文件做出如下處理:簡體轉繁體、文字取代(從指定的 Excel 試算表取得搜尋 / 取代清單)、醒目提示(同樣是從 Excel 試算表中讀取清單)、另存為純文字檔、以及將註解內容匯出為一個 Excel 試算表。
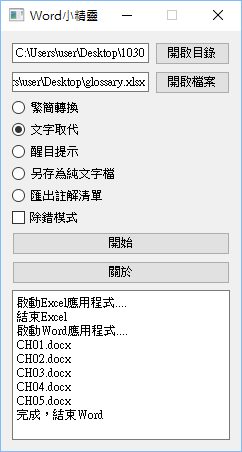
事實上這支工具的部份實作細節,已經在先前的兩篇文章裡約略說明:
由 darkranger 在 週六, 11/05/2016 - 19:25 發表,更新日期:週一, 12/19/2022 - 11:49
類似於先前程式設計初學指南的風格,本文是嘗試對 Linux 作業系統的初學者,提供一些概括性的指引,所以不會有任何具體的指令或操作流程。但仍希望透過這些經驗分享,可以幫助初學者形塑出適當的學習路徑。
如同先前的程式設計初學指南,本文會先簡單交代 DR 早年的 Linux 學習歷程,讓本文的觀點能夠比較容易被理解。
就目前印象所及,DR 第一次認知到 Linux 的存在,應該是一則關於《雷神之鎚 III》(Quake III Arena,1999)的消息,內容提到這款遊戲為 Windows 及 Linux 釋出了測試版本。消息雖短,卻足以讓人意識到,原來 Linux 是有別於 Windows 的另一種作業系統。
由 darkranger 在 週六, 09/17/2016 - 21:08 發表,更新日期:週三, 09/21/2016 - 13:44
許多人都知道,Microsoft Word 有一項繁簡轉換的功能,能夠將文字在簡體中文及繁體中文之間互相轉換。雖然這確實是很方便的功能,但如果真的將這項功能應用在工作實務上,則很快就會意識到,它的轉換結果存在著一些問題。
儘管我們大概都明白,對於中文繁簡轉換,很難有完美的系統性解決方案(看看現今中文維基百科的繁簡亂象就知道了),因而轉換後的結果勢必都還要再做人工校正,以保障其正確性。然而 Word 的繁簡轉換功能卻存在著一些理應可以修復、卻一直沒有處理的 Bug(包含目前最新的 Word 2016 在內)。因此,本文接下來的內容會說明這些問題,讓有意使用 Word 繁簡轉換功能的人士可以留意到當中的地雷。
關於【使用台港澳等地字元】這個選項,目前並無已知的問題,若停用會出現諸如簡體的「并」字無法轉換成繁體「並」字的狀況,反之若啟用該選項則沒有負面效果。因此在做繁簡轉換時,這個選項應是必選且無害的。
由 darkranger 在 週六, 09/03/2016 - 21:56 發表
在工作的時候,一直看稿改稿查資料,有時候精神會消耗得很快。而每當 DR 覺得自己開始精神耗弱時,就會逛逛網站、看看文章,試圖藉此提振一下自己的精神。然而最近 DR 讀到一篇文章,內容提到其實「多工切換」正是使精神加劇耗損的元兇。因此若四處瀏覽各種訊息,不僅未必達到回神的效果,反而有可能變得越加疲倦。因此,真正適當的緩解方式,是執行一項能夠專注的活動,讓腦袋在單工思緒中逐步復原。
DR 發覺這似乎還蠻有道理的,於是便開始設想幾種可能的方案。然而其中的許多方案若用在上班時間裡,要嘛不易執行、要嘛有觀感問題。想了一下,又蹦出了一項方案:不如做一支可以練習英打速度的程式,這或許是一個幫助提神的好辦法。
在初步的構思階段裡,DR 原先期望這支 Python 程式能夠有一個稍微華麗一點的文字介面,例如在打字的同時能夠有一行顯示倒數計時,提醒使用者剩下多少時間。但查了一下,發現這項需求似無可輕鬆達成的跨平台方案,後來便決定不要在這方面著墨太多,並回歸到最原始、一行一行的文字輸出入介面。
由 darkranger 在 週六, 08/20/2016 - 20:54 發表,更新日期:週一, 12/05/2016 - 15:10
日前 DR 協助同事檢查公司的郵件主機,想確認究竟對外開放了哪些服務。而對於這類需求,DR 總是認為使用 Nmap 做埠口掃描是很方便的檢查方式。於是就在自己的 EC2 主機上使用 Nmap,從外部網路來掃描該郵件主機。然而之後 DR 就收到了來自 Amazon 的一封信,標題為「Your Amazon EC2 Abuse Report」,內容則是可疑活動的記錄與警告,使得 DR 必須很快回信解釋一下原由。
經對方的回覆後才知道,原來在 EC2 主機上做這類動作,是要事先填表單申請的,真是孤陋寡聞。詳情可見官方說明頁面:Vulnerability and Penetration Testing。
頁面